Overview¶
PixStor Search provides searchable rich metadata of all files on a PixStor file system.
PixStor Search comprises several components:
Ingest¶
PixStor Search provides a scale out file system scanner, which will interrogate files in the system (either incrementally or in-full), to add them to the database
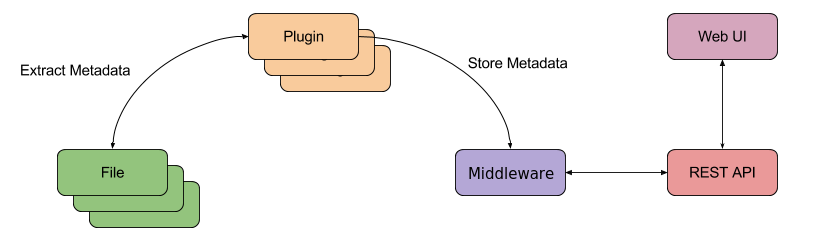
Metadata Extraction¶
As part of the ingest process, metadata is extracted from the files. This includes traditional filesystem metadata (such as creation time, owner and file size), but in addition the file content is interrogated to provide Deep or Rich Metadata.
Developers can write plugins for this process, enabling support for both a wider range, and a greater depth of metadata than is supplied as standard.
The metadata process has both a scale-out philosophy, and the ability to off-load processing.
High-Performance Scale-Out Database¶
Stores all metadata known by PixStor Search.
Proxy generation¶
As part of the ingest process, zero or more proxies are created for files. These allow user interfaces to display file content, both in an overview fashion, and in greater depth (e.g. a thumbnail and a playable movie).
Again, developers can write plugins for these processes, which can make use of internal asynchronous processing.
REST API¶
For developers, a RESTful API based on the Collection+JSON standard is available - providing scalable, authenticated access to Database.
REST APIs provide a simple mechanism to programmatically access PixStor Search’s stored metadata.
Web UI¶
The Web UI, built using the REST API, provides an authenticated rich interface for users to query the core PixStor Search database and proxy store.